

Semantic AI search
 hero image
hero image
Semantic search enables you to search for content based on its meaning, going beyond just keyword matching, while maintaining fast response times.
What you’ll need
The core component is the database, and we’ll be using Supabase (Postgres database with Pgvector extension)
All other tools, including your choice of data providers, remain flexible. This could be a database or CMS. For this example, we’ll use @supabase/supabase-js to interact with the database, and Blitz.js as the full-stack framework to handle both server-side and frontend logic.
Intro
We’ll demonstrate a real-life example currently in production, which you can test directly. We’ve implemented this solution for our conference portal GitNation. This is our product where we collect content and people who attend our conferences around the world.
Our specific use case was straightforward: we wanted to allow users to easily search our video content. What’s unique is that our search extends beyond video titles and descriptions—allowing searches based on every single word spoken by our conference speakers. Imagine searching YouTube by what’s actually said inside the videos—that’s precisely what we’ve achieved! Similar to how businesses can build native ChatGPT shopping apps tailored to their brand, our semantic search demonstrates the power of customized AI implementations.
Getting started
Everything begins with content, because you’ll need something to search.
For our example, we’re using transcripts from conference talks and workshops generated using Whisper, which, by the way, you can read about in our other article. Of course, this method can be applied to any textual content or even product descriptions in a catalog.
Database
We need to store our searchable content in a database. It’s easy with Supabase:
- Create a free Supabase account.
- Enable the pgvector extension.
CREATE EXTENSION IF NOT EXISTS vector;
Next, set up a table to store our searchable content:
CREATE TABLE "SearchIndex" (
id bigserial PRIMARY KEY,
"contentId" int,
text text,
embedding vector(1536)
);
Explanation of columns:
-
contentId: Reference ID for original content (video, product).
-
text: The actual searchable text.
-
embedding: Semantic vectors obtained via OpenAI.
That’s it. Next, we just need to populate the table with content.
Content upload
Uploading content involves splitting large texts into manageable chunks, improving navigation and accuracy. Imagine large manuals or books being searchable down to specific paragraphs.
We recommend chunk sizes around 500 tokens for better semantic accuracy:
import { encode } from 'gpt-3-encoder';
const CHUNK_LIMIT = 200;
export const CHUNK_MINIMAL = 50;
export const chunkTextByTokenLimit = (text, limit = CHUNK_LIMIT) => {
const textChunks = [];
if (encode(text).length > limit) {
const splittedText = text.split('. ');
let chunkText = '';
splittedText.forEach((sentence) => {
const sentenceTokenLength = encode(sentence).length;
const chunkTextTokenLength = encode(chunkText).length;
if (sentenceTokenLength + chunkTextTokenLength > limit) {
textChunks.push(chunkText);
chunkText = '';
}
if (sentence[sentence.length - 1] && sentence[sentence.length - 1].match(/[a-z0-9]/i)) {
chunkText += `${sentence}. `;
} else {
chunkText += `${sentence} `;
}
});
textChunks.push(chunkText.trim());
} else {
textChunks.push(text.trim());
}
let resultChunks = textChunks.map((chunk) => {
const trimmedText = chunk.trim();
return {
content: trimmedText,
contentLength: trimmedText.length,
contentTokens: encode(trimmedText).length,
};
});
if (resultChunks.length > 1) {
resultChunks = resultChunks.filter((chunk, index) => {
const prevChunk = resultChunks[index - 1];
if (chunk.contentTokens < CHUNK_MINIMAL && prevChunk) {
prevChunk.content += chunk.content;
prevChunk.contentLength += chunk.contentLength;
prevChunk.contentTokens += chunk.contentTokens;
return false;
}
return true;
});
} else {
resultChunks = resultChunks.filter(Boolean);
}
return resultChunks;
};
After splitting, create embeddings and store them:
const createEmbedding = async (input) => {
const inputFormatted = input.toLowerCase().replace(/\n/g, ' ');
try {
const embeddingRes = await openAi.createEmbedding({
model: 'text-embedding-3-small',
input: inputFormatted,
});
const [{ embedding }] = embeddingRes.data.data;
return embedding;
} catch (error) {
throw error;
}
};
const processCallBacks = async (promisesChunks, callback, contentId) => {
for (const chunk of promisesChunks) {
await Promise.all(
chunk.map(async (data) => {
try {
let embed;
// make sure we under OpenAi limit
if (encode(data.content).length < 1500) {
embed = await createEmbedding(data.content);
} else {
embed = await createEmbedding(data.content.slice(0, 800));
}
await callback(data, embed);
} catch (error) {
Logger.error(`Text processing error. id: ${contentId}`, error);
throw error;
}
}),
);
}
};
export const createContentEmbeds = async (content) => {
try {
let contentTextChunks;
contentTextChunks = chunkTextByTokenLimit(content.transcription);
// Lodash _.chunk() Method
const promisesTextChunks: ResultChunk[][] = chunk(contentTextChunks, 2);
await processCallBacks(
promisesTextChunks,
(data, embed) => {
return supabase
.from('SearchIndex')
.insert({
contentId: content.id,
text: data.content,
embedding: embed,
})
.then(({ error }) => {
if (error) {
throw error;
}
});
},
content.id,
);
return 'Done';
} catch (error) {
throw error;
}
};
After you’ve reviewed these functions, you’re ready to perform semantic searches.
First queries
To perform searches, we first transform the user’s query into embeddings:
export const semanticSearch = async (searchTerm) => {
const embedding = await createEmbedding(searchTerm);
};
Then, create a robust Postgres function for performing searches with semantic relevance and optimized performance:
CREATE OR REPLACE FUNCTION semantic_search (
query_embedding VECTOR(1536),
match_threshold FLOAT,
match_count INT
)
RETURNS TABLE (
id BIGINT,
content TEXT,
similarity FLOAT
)
LANGUAGE sql STABLE
AS $$
SELECT
"SearchIndex".id,
"SearchIndex"."contentId",
1 - ("SearchIndex".embedding <=> query_embedding) AS similarity
FROM
"SearchIndex"
WHERE
1 - ("SearchIndex".embedding <=> query_embedding) > match_threshold
ORDER BY
similarity DESC
LIMIT
match_count;
$$;
Finally, call this optimized function within your application:
export const semanticSearch = async (searchTerm, elementsCount: number = 5000) => {
const embedding = await createEmbedding(searchTerm);
const { data: results, error } = await supabase.rpc('semantic_search', {
query_embedding: embedding,
match_threshold: 0.78,
match_count: elementsCount,
});
return results;
};
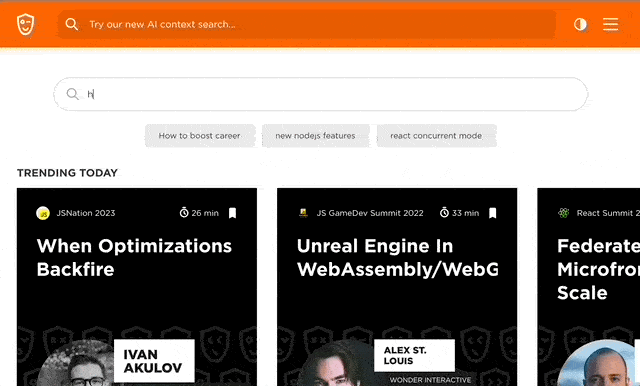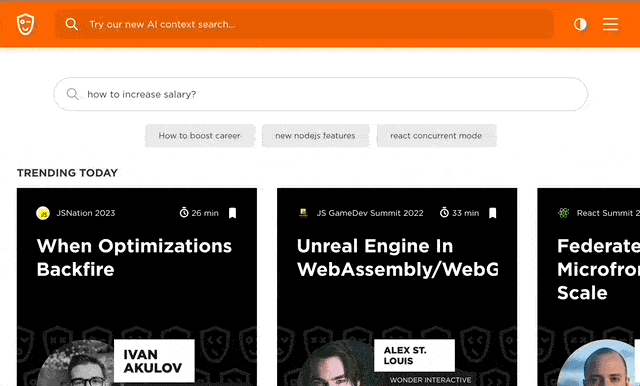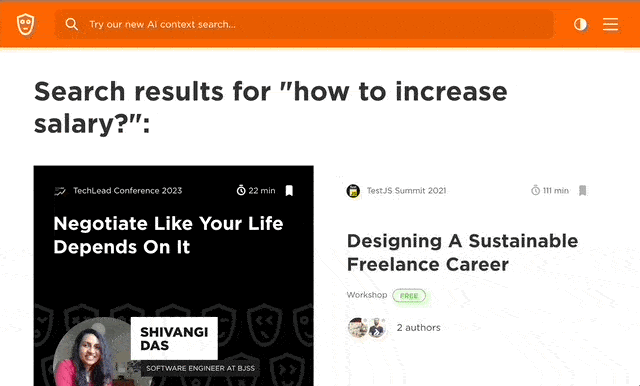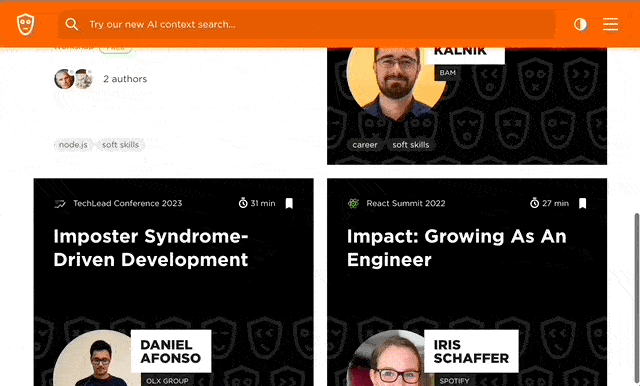
Finally, it’s time for images! For the query “awesome AI features,” we get the following results.
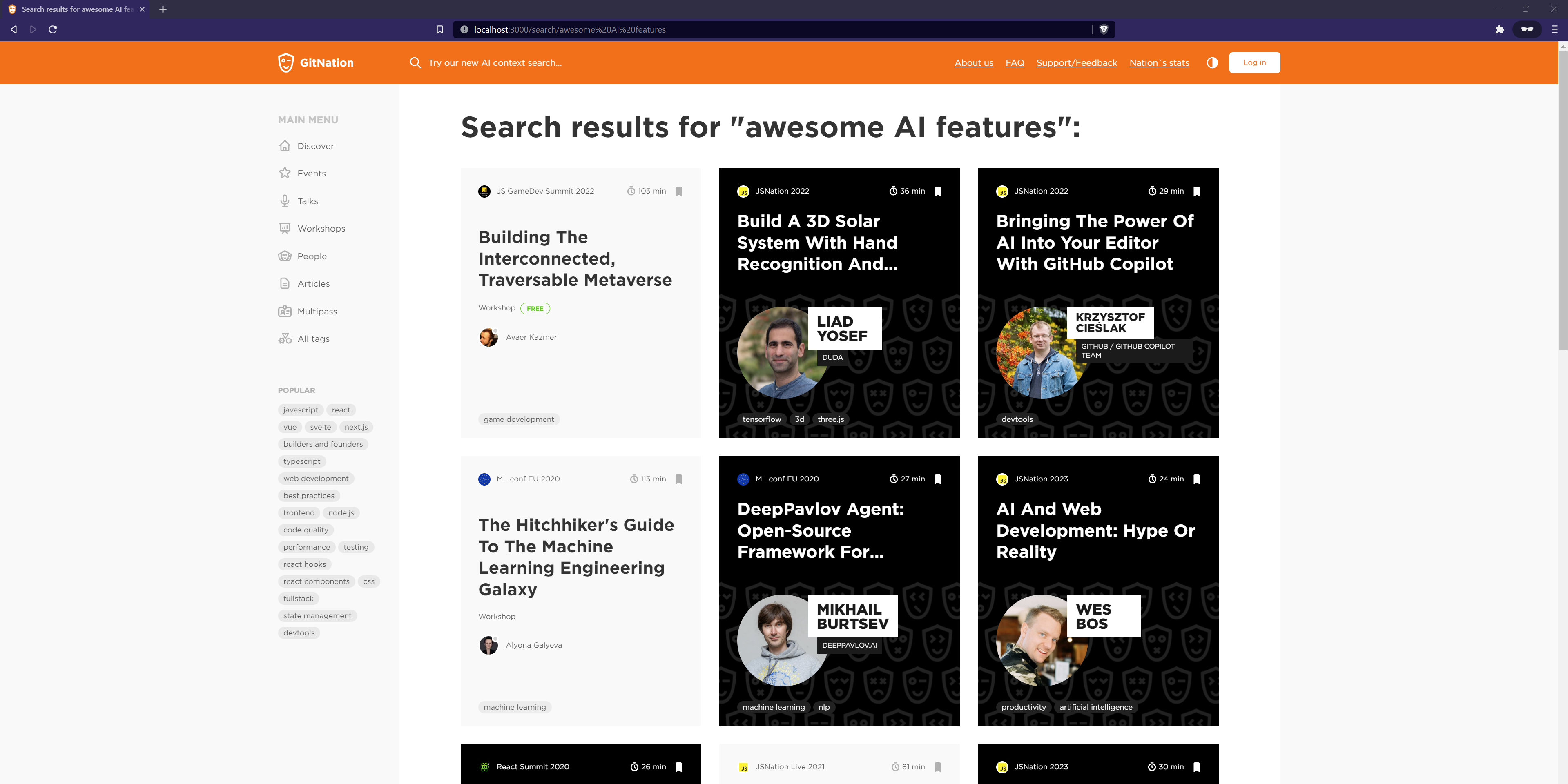 search results
search results
The results we get from the initial implementation are highly relevant and match our expectations perfectly. However, there was a significant drawback—the query execution took approximately 6 seconds.
Another challenge we noticed was that sometimes OpenAI’s interpretation could slightly deviate from what users intended. For example, the query “great react” might be misunderstood as user reactions rather than content about React.js. This primarily arises from the lack of broader context within the search query itself.
Optimisation
To enhance the query speed from several seconds down to around 200ms, we’ll implement additional optimization steps. A proven approach involves reducing the number of database rows that must be searched since performance scales linearly with dataset size. By incorporating PostgreSQL’s built-in full-text search (FTS) to pre-filter records before performing semantic search, we significantly optimize performance.
This hybrid method combines the strengths of keyword-based and semantic search, providing faster and more relevant results. You can explore PostgreSQL’s full-text search capabilities further here. Let’s briefly cover these optimization steps below.
DB optimisation
We will add a new column named ‘fts’ to the ‘SearchIndex’ table, which will be used to store the searchable index of the ‘title’ and ‘description’ columns.
ALTER TABLE "SearchIndex"
ADD COLUMN fts tsvector GENERATED ALWAYS AS (to_tsvector('english', text)) STORED;
To further boost query performance, let’s add a GIN index to the fts column:
CREATE INDEX "SearchIndex" ON text USING GIN (fts);
You can now quickly test this functionality with queries such as:
SELECT * FROM "SearchIndex" WHERE fts @@ to_tsquery('awesome | AI | features');
Next, optimize the indexing of the vector embeddings as well. Rather than using a small lists parameter, we recommend choosing a value between 50 and 200 depending on your dataset size. Additionally, we recommend utilizing the newer and more performant hnsw indexing method provided by pgvector: link
CREATE INDEX ON "SearchIndex" USING hnsw (embedding vector_cosine_ops);
Great! We are ready to update our query and check the results.
Query optimisation
Now, we’ll enhance our PostgreSQL function with both full-text and semantic search:
CREATE OR REPLACE FUNCTION semantic_search (
query_string TEXT,
query_embedding VECTOR(1536),
similarity_threshold FLOAT,
match_count INT
)
RETURNS TABLE (
id BIGINT,
contentId INT,
similarity FLOAT
)
LANGUAGE plpgsql STABLE AS $$
BEGIN
RETURN QUERY
WITH filtered_content AS (
SELECT * FROM "SearchIndex"
WHERE fts @@ to_tsquery(query_string)
)
SELECT
filtered_content.id,
filtered_content."contentId",
1 - (filtered_content.embedding <=> query_embedding) AS similarity
FROM filtered_content
WHERE 1 - (filtered_content.embedding <=> query_embedding) > similarity_threshold
ORDER BY similarity DESC
LIMIT match_count;
END;
$$;
Result query
Finally, here’s how you execute this optimized search query from your application:
export const semanticSearch = async (searchTerm, elementsCount = 5000) => {
const embedding = await createEmbedding(searchTerm);
const formattedQuery = searchTerm.toLowerCase().replace(/\s+/g, ' | ');
const { data } = await supabase.rpc('semantic_search', {
query_string: formattedQuery,
query_embedding: embedding,
similarity_threshold: 0.78,
match_count: elementsCount,
});
return data;
};
The results after this optimization remain accurate and relevant, yet the query execution time improves dramatically — from about 6 seconds down to roughly 500 milliseconds, a twelvefold speed increase!
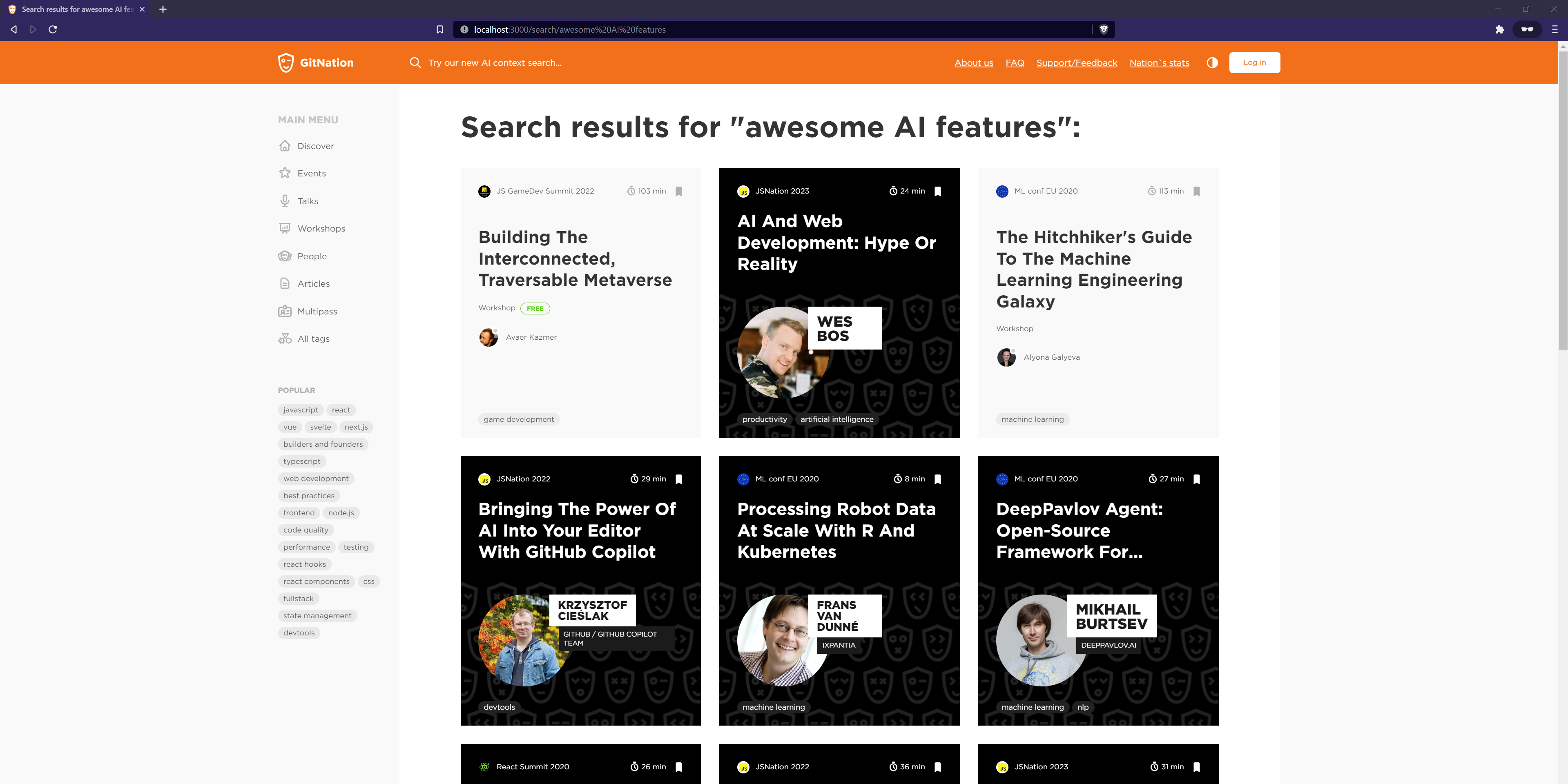 search results
search results
Want semantic search in your product?
We’ve built this in production — for our own conference portal and for clients, by combining classic full-text search with modern semantic vector search. If you want to add meaning-aware search to your web application, CMS, or content platform, we can scope and build it for you. Let’s talk!





